_index
Core Concepts
Learn the most important concepts you'll need for system design interviews, put together by FAANG managers and staff engineers.
While understanding a common structure for the interview in Delivery will help you pilot your interview, it won't be sufficient for you to solve the problems you'll encounter in the interview. For this, you'll need to understand some core concepts of system design.
Below are the most common concepts you'll encounter in a system design interview.
Scaling
One of the most important topics in many system design questions is how to deal with scale. While there are a lot of ways to do this, your interviewer is definitely going to want you to know how to scale a system "horizontally". Horizontal scaling is all about adding more machines to a system to increase its capacity. This is in contrast to vertical scaling, which is the process of adding more resources to a single machine to increase its capacity.
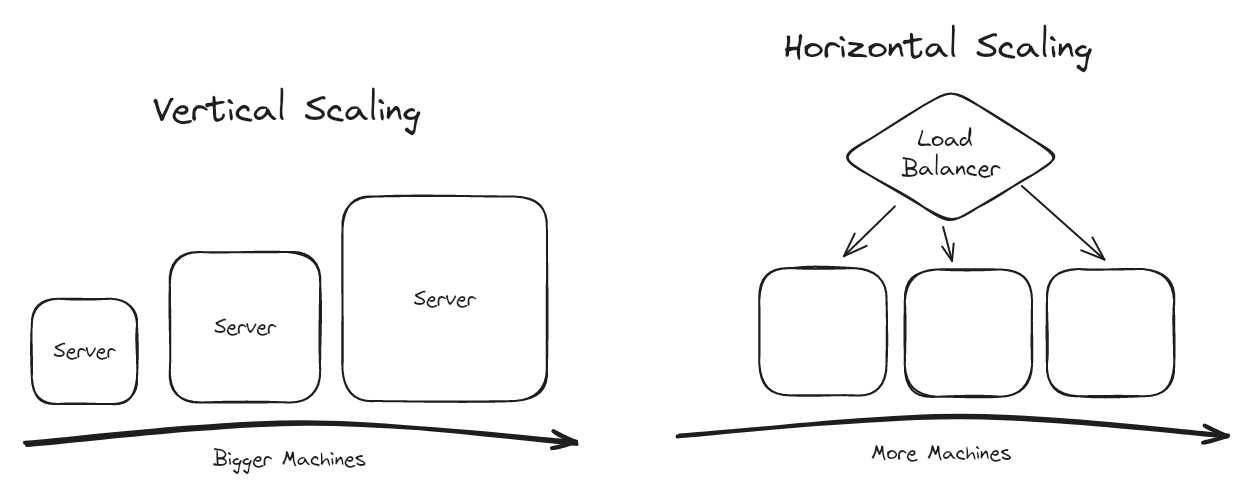
More senior interviewers will recognize that vertical scaling actually requires significantly less incremental complexity. If you can estimate your workload and determine that you can scale vertically for the forseeable future, this is often a better solution than horizontal scaling. Many systems can scale vertically to a surprising degree.
Adding machines isn't a free lunch. Oftentimes by scaling you're forced to contend with the distribution of work, data, and state across your system. This is a common source of yellow flags in system design interviews, so let's discuss them a bit more in detail.
Inexperienced candidates tend to make two mistakes: (1) they leap to horizontal scaling to solve any performance problem, even when it's not necessary, and (2) they don't consider the implications of horizontal scaling on the rest of the system. When you encounter a scaling bottleneck, make sure you're not throwing machines at a poor design.
When horizontal scaling is the right solution, you'll need to consider how to distribute work across your machines. Most modern systems use a technique called "Consistent Hashing" to distribute work across a set of machines - this is a technique that arranges both data and machines in a circular space called a "hash ring", allowing you to add or remove machines with minimal data redistribution.
Work Distribution
The first challenge of horizontal scaling is getting the work to the right machine. This is often done via a load balancer, which will choose which node from a group to use for an incoming request. While load balancers often come with many different strategies (e.g. least connections, utilization-based, etc), simple round robin allocation is often sufficient. For asynchronous jobs work, this is often done via a queueing system.Work distribution needs to try to keep load on the system as even as possible. For example, if you're using a hash map to distribute work across a set of nodes, you might find that one node is getting a disproportionate amount of work because of the distribution of incoming requests. The scalability of your system ultimately depends on how effectively you can remediate this. If one node is 90% busy and the remaining are 10% busy, you're not getting much out of your horizontal scaling.
Data Distribution
You'll also need to consider how to distribute data across the system. For some systems, this implies keeping data in-memory on the node that's processing the request. More frequently, this implies keeping data in a database that's shared across all nodes. Look for ways to partition your data such that a single node can access the data it needs without needing to talk to another node. If you do need to talk to other nodes (a concept known as "fan-out"), keep the number small. A common antipattern is to have requests which fan out to many different nodes and then the results are all gathered together. This "scatter gather" pattern can be problematic because it can lead to a lot of network traffic, is sensitive to failures in each connection, and suffers from tail latency issues if the final result is dependent on every response.If your system design problem involves geography, there's a good chance you have the option to partition by some sort of REGION_ID. For many systems that involve physical locations, this is a great way to scale because for many problems a given user will only be concerned with data in or around a particular location (e.g. a user in the US doesn't need to know about data in Europe).Inherently, horizontal scaling on data introduces synchronization challenges. You're either reading and writing data to a shared database which is a network hop away (≈ 1-10ms, ideally) or you're keeping multiple redundant copies across each of your servers. This means race conditions and consistency challenges! Most database systems are built to resolve some of the these problems directly (e.g. by using transactions). In other cases, you may need to use a Distributed Lock. Regardless, you'll need to be prepared to discuss how you're going to keep your data Consistent.
CAP Theorem
Locking
In our system we may have shared resources which can only be accessed by one client at a time. An example might be a shared counter (like inventory units) or an interface to a physical device (drawbridge up!). Locking is the process of ensuring that only one client can access a shared resource at a time.Locks happen at every scale of computer systems: there are locks in your operating system kernel, locks in your applications, locks in the database, and even distributed locks - hence they are a common topic in system design interviews. Locks are important for enforcing the correctness of our system but can be disastrous for performance.In most system design interviews, you'll be forced to contend with locks when you consider race conditions. A race condition, if you remember, is a situation where multiple clients are trying to access the same resource at the same time. This can lead to data corruption, lost updates, and other bad things.There's three things to worry about when employing locks:Granularity of the lock We want locks to be as fine-grained as possible. This means that we want to lock as little as possible to ensure that we're not blocking other clients from accessing the system. For example, if we're updating a user's profile, we want to lock only that user's profile and not the entire user table.Duration of the lock We want locks to be held for as short a time as possible. This means that we want to lock only for the duration of the critical section. For example, if we're updating a user's profile, we want to lock only for the duration of the update and not for the entire request.Whether we can bypass the lock In many cases, we can avoid locking by employing an "optimistic" concurrency control strategy, especially if the work to be done is either read-only or can be retried. In an optimistic strategy we're going to assume that we can do the work without locking and then check to see if we were right. In most systems, we can use a "compare and swap" operation to do this.Optimistic concurrency control makes the assumption that most of the time we won't have contention (or multiple people trying to lock at the same time) in a system, which is a good assumption for many systems! That said, not all systems can use optimistic concurrency control. For example, if you're updating a user's bank account balance, you can't just assume that you can do the update without locking.An optimistic update
Indexing
Indexing is about making data faster to query. In many systems, we can tolerate slow writes but we can't tolerate slow reads. Indexing is the process of creating a data structure that makes reads faster.The most basic method of indexing is simply keeping our data in a hash map by a specific key. When we need to grab data by that key, we can do so in O(1) time. Suddenly we don't need to scan the entire dataset to find the data we need.Another way of indexing is to keep our data in a sorted list. This allows us to do binary search to find the data we need in O(log n) time. This is a common way of indexing data in databases.There are many different types of indexes but the principle is the same: do a minimal amount of up-front work so that your reads can be extra fast.
Indexing in Databases
Most questions of indexing will happen inside your database. Depending on your database choice, you'll have different options for indexing. For example, most relational databases allow you to create indexes on any column or group of columns in a table. This isn't unbounded, however. While databases like DynamoDB allow you to create many secondary indexes, for databases like Redis you're on your own to design and implement your own indexing strategy.If you can do your indexing in your primary database, do it! Databases have been battle-honed over decades for exactly this problem, so don't reinvent the wheel unless you have to.
Specialized Indexes
In addition to the basic indexing strategies, there are many specialized indexes that are used to solve specific problems. For example, geospatial indexes are used to index location data. This is useful for systems that need to do things like find the nearest restaurant or the nearest gas station. Vector databases are used to index high-dimensional data. This is useful for systems that need to do things like find similar images or similar documents. And full-text indexes are used to index text data. This is useful for systems that need to do things like search for documents or search for tweets.Many mature databases like Postgres support extensions that allow you to create specialized indexes. For example, Postgres has a PostGIS extension that allows you to create geospatial indexes. If not, you'll need to maintain your indexes externally.ElasticSearch is our recommended solution for these secondary indexes, when it can work. ElasticSearch supports full-text indexes (search by text) via Lucene, geospatial indexes, and even vector indexes. You can set up ElasticSearch to index most databases via Change Data Capture (CDC) where the ES cluster is listening to changes coming from the database and updating its indexes accordingly. This isn't a perfect solution! By using CDC, you're introducing a new point of failure and a new source of latency, the data read out of your search index is going to be stale, but that may be ok.It's very common for candidates to introduce ElasticSearch as a potential solution to their problem without understanding its limitations or explaining how it's used. Make sure you brush up on the fundamentals so that you're ready on interview day.ElasticSearch as a secondary index
Communication Protocols
Protocols are an important part of software engineering, but most system design interviews won't cover the full OSI model. Instead, you'll be asked to reason about the communication protocols you'll use to build your system. You've got two different categories of protocols to handle: internal and external. Internally, for a typical microservice application which consistitues 90%+ of system design problems, either HTTP(S) or gRPC will do the job. Don't make things complicated.Externally, you'll need to consider how your clients will communicate with your system: who initiates the communication, what are the latency considerations, and how much data needs to be sent.Across choices, most systems can be built with a combination of HTTP(S), SSE or long polling, and Websockets. Browsers and apps are built to handle these protocols and they're easy to use and generally speaking most system design interviews don't deal with clients that need to have custom, high-performance protocols.External
- Use HTTP(S) for APIs with simple request and responses. Because each request is stateless, you can scale your API horizontally by placing it behind a load balancer. Make sure that your services aren't assuming dependencies on the state of the client (e.g. sessions) and you're good to go.
- If you need to give your clients near-realtime updates, you'll need a way for the clients to receive updates from the server. Long polling is a great way to do this that blends the simplicity and scalability of HTTP with the realtime updates of Websockets. With long polling, the client makes a request to the server and the server holds the request open until it has new data to send to the client. Once the data is sent, the client makes another request and the process repeats. Notably, you can use standard load balancers and firewalls with long polling - no special infrastructure needed.
- Websockets are necessary if you need realtime, bidirectional communication between the client and the server. From a system design perspective, websockets can be challenging because you need to maintain the connection between client and server. This can be a challenge for load balancers and firewalls, and it can be a challenge for your server to maintain many open connections. A common pattern in these instances is to use a message broker to handle the communication between the client and the server and for the backend services to communicate with this message broker. This ensures you don't need to maintain long connections to every service in your backend.
- Lastly, Server Sent Events (SSE) are a great way to send updates from the server to the client. They're similar to long polling, but they're more efficient for unidirectional communication from the server to the client. SSE allows the server to push updates to the client whenever new data is available, without the client having to make repeated requests as in long polling. This is achieved through a single, long-lived HTTP connection, making it more suitable for scenarios where the server frequently updates data that needs to be sent to the client. Unlike Websockets, SSE is designed specifically for server-to-client communication and does not support client-to-server messaging. This makes SSE simpler to implement and integrate into existing HTTP infrastructure, such as load balancers and firewalls, without the need for special handling.
Statefulness is a major source of complexity for systems. Where possible, relegating your state to a message broker or a database is a great way to simplify your system. This enables your services to be stateless and horizontally scalable while still maintaining stateful communication with your clients.
In Server-Sent Events (SSE), the server uses plain HTTP response headers to establish and maintain the stream.
Required headers
Content-Type: text/event-stream→ tells the client this is an SSE stream.Cache-Control: no-cache→ prevents proxies/browsers from caching the stream.Connection: keep-alive→ keeps the HTTP connection open.
Optional / Recommended headers
-
Transfer-Encoding: chunked→ if server streams without knowing total length. -
Access-Control-Allow-Origin: *→ for cross-origin SSE. -
X-Accel-Buffering: no(NGINX) → disables proxy buffering. -
Keep-Alive: timeout=...→ may be added by server for persistent connection.
Security
When designing production systems, security should be top of mind. While system design interviews are rarely going to require you to do detailed security testing of your design, they are looking for you to emphasize security where appropriate. This means that you should be prepared to discuss how you'll secure your system at every level. Some of the most common security concerns are:
Authentication / Authorization
In many systems you'll expose an API to external users which needs to be locked down to only specific users. Delegating this work to either an API Gateway or a dedicated service like Auth0 is a great way to ensure that you're not reinventing the wheel. Your interviewer may want you to discuss the finer details like how specific entities are secured, but often it's sufficient to say "My API Gateway will handle authentication and authorization".
Encryption
Once you're handling sensitive data, it's important to make sure you're keeping it from snooping eyes. You'll want to cover both the data in transit (e.g. via protocol encryption) and the data at rest (e.g. via storage encryption). HTTPS is the SSL/TLS protocol that encrypts data in transit and is the standard for web traffic. If you're using gRPC it supports SSL/TLS out of the box. For data at rest, you'll want to use a database that supports encryption or encrypt the data yourself before storing it.For sensitive data, it can often be useful for the end-user to control the keys. This is a common pattern in systems that need to store sensitive data. For example, if you're building a system that stores user data, you might want to encrypt that data with a key that's unique to each user. This way, even if your database is compromised, the data is still secure.
Data Protection
Data protection is the process of ensuring that data is protected from unauthorized access, use, or disclosure. Frequently, production systems are concerned with data that's sensitive when exposed but might not be within an authorization path (e.g. a user's data might be exposed via a createFriendRequest endpoint). Many exposures of this sort are discovered by scraping endpoints, so having some sort of rate limiting or request throttling is a good idea.
Monitoring
Once you've designed your system, some interviewers will ask you to discuss how you'll monitor it. The idea here is simple: candidates who understand monitoring are more likely to have experience with actual systems in production. Monitoring real systems is also a great way to learn about how systems actually scale (and break).Monitoring generally occurs at 3 levels, and it's useful to name them.
Infrastructure Monitoring
Infrastructure monitoring is the process of monitoring the health and performance of your infrastructure. This includes things like CPU usage, memory usage, disk usage, and network usage. This is often done with a tool like Datadog or New Relic. While a disk usage alarm may not break down your service, it's usually a leading indicator of problems that need to be addressed.
Service-Level Monitoring
Service-level monitoring is the process of monitoring the health and performance of your services. This includes things like request latency, error rates, and throughput. If your service is taking too long to respond to requests, it's likely that your users are having a bad time. If throughput is spiking, it may be that you're handling more traffic or your system may be misbehaving.
Application-Level Monitoring
Application-level monitoring is the process of monitoring the health and performance of your application. This includes things like the number of users, the number of active sessions, and the number of active connections. This could also include key business metrics for the business. This is often done with a tool like Google Analytics or Mixpanel. This is often the most important level of monitoring for product design interviews.
Not sure where your gaps are?
Mock interview with an interviewer from your target company. Learn exactly what's standing in between you and your dream job.